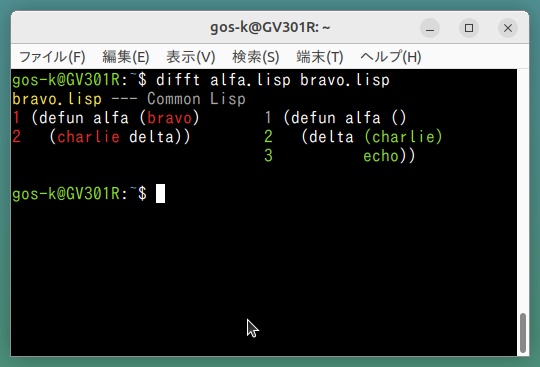
通常プログラムを書いていると、関数を書いて、その関数を呼び出す関数を書いて、というような木構造とか階層構造とか複雑になっていく。
これを辿る方法について。
実行環境はlemのslime上で、ccl 1.12.1が前半でsbcl 2.2.9が後半。
slimeの挙動
slimeには M-. で関数定義にジャンプする機能があるが、これは swank の find-definitions-for-emacs により実現されており、repl上からも使える。
(swank:find-definitions-for-emacs "mapcar")
(("#'MAPCAR" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/lists.lisp") (:POSITION 26761) NIL))
("(COMPILER-MACRO MAPCAR)" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/compiler/optimizers.lisp") (:POSITION 33286) NIL)))
mapcar という名前だけからは複数の該当個所が出てくる。
逆に M-_ で関数利用先は swank の xrefs。
(swank:xrefs '(:calls :macroexpands :binds :references :sets :specializes) "mapcar")
((:CALLS ("#'UIOP/UTILITY:WHILE-COLLECTING" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/tools/asdf.lisp") (:POSITION 57642) (:SNIPPET "(defmacro while-collecting ((&rest colle")))
("#'SWANK::MAP-IF" (:LOCATION (:FILE "/home/gos-k/.roswell/lisp/quicklisp/dists/quicklisp/software/slime-v2.27/swank.lisp") (:POSITION 105172) (:SNIPPET "(defun map-if (test fn &rest lists)
\"L")) )
("#'SWANK::SCORE-COMPLETION" (:LOCATION (:FILE "/home/gos-k/.roswell/lisp/quicklisp/dists/quicklisp/software/slime-v2.27/contrib/swank-fuzzy.lisp") (:POSITION 29566) (:SNIPPET "(defun score-completion (completion shor")))
("#'CCL::FIXED-VALUES-OP" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/level-1/l1-typesys.lisp") (:POSITION 32586) NIL))
("(:METHOD CCL::FORCE-BREAK-IN-LISTENER (#<STANDARD-CLASS PROCESS>))" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/level-1/l1-events.lisp") (:POSITION 3880) NIL))
("#'CCL::DECOMP-LAMBDA-LIST" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/compiler/nx-basic.lisp") (:POSITION 43172) NIL))
("#'CCL::NX1-TYPESPEC-FOR-TYPEP" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/compiler/nx1.lisp") (:POSITION 2900) NIL))
("#'CCL::DEFAULT-SETF" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/macros.lisp") (:POSITION 26221) NIL))
("#'RESTART-BIND" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/macros.lisp") (:POSITION 8651) NIL))
("#'CCL::BITOPF" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/macros.lisp") (:POSITION 52042) NIL))
("#'CCL::LONG-FORM-DEFINE-METHOD-COMBINATION" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/method-combination.lisp") (:POSITION 24944) NIL))
("#'CCL::REFERENCE-METHOD" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/macros.lisp") (:POSITION 126784) NIL))
("#'POP" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/setf.lisp") (:POSITION 30800) NIL))
("#'PUSHNEW" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/setf.lisp") (:POSITION 30051) NIL))
("#'PUSH" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/setf.lisp") (:POSITION 29432) NIL))
("#'DECF" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/setf.lisp") (:POSITION 14220) NIL))
("#'INCF" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/setf.lisp") (:POSITION 13504) NIL))
("#'DEFSETF" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/setf.lisp") (:POSITION 8755) NIL))
("#'CCL::DEFSTRUCT-BOA-CONSTRUCTOR" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/defstruct-lds.lisp") (:POSITION 14720) NIL))
("#'CCL::%TEMP-PUSH" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/compiler/nxenv.lisp") (:POSITION 37263) NIL))
("#'CCL::TRACE-PRINT-BODY" (:LOCATION (:FILE "/home/gos-k/.roswell/impls/x86-64/linux/ccl-bin/1.12.1/lib/encapsulate.lisp") (:POSITION 11734) NIL))))
これらはテキストエディタを前提としてるので、カーソル位置から名前を取り、それによって検索している。
欲しいものに近いがちょっと違って、指定した関数の中で呼び出されている関数のリストが欲しい。
呼び出している関数のリスト
xrefs に :callees を渡すと取れるみたいだが、cclだと動かなかったのでsbclで試す。
repl上で2つ関数定義する。
(defun alfa () (pprint :alfa))
(defun bravo () (alfa))
bravoを指定する。
(swank:xrefs '(:callees) "bravo")
呼び出してるalfaが取れる。
repl上で定義してるのでソースファイルがないエラーになってる。
((:CALLEES ("ALFA" (:ERROR "Error: DEFINITION-SOURCE of function ALFA did not contain meaningful information."))))
alfaを指定する。
(swank:xrefs '(:callees) "alfa")
呼び出しているpprintが取れる。
((:CALLEES
("PPRINT"
(:LOCATION (:FILE "/home/gos-k/.roswell/src/sbcl-2.2.9/src/code/print.lisp") (:POSITION 6690)
(:SNIPPET "(defun pprint (object &optional stream)
\"Prettily output OBJECT preceded by a newline.\"
(declare (explicit-check))
(let ((*print-pretty* t)
(*print-escape* t)
(stream (out-stream-from-designator stream)))
(terpri stream)
(outp")))))
これを再帰的に行うと、
(defun trace-functions (name)
(pprint name)
(let* ((refs (swank:xrefs '(:callees) name))
(callees (last (first refs))))
(dolist (callee callees)
(trace-functions (first callee)))))
(trace-functions "bravo")
"bravo"
"ALFA"
"PPRINT"
"TERPRI"
多分関数が辿れた。
ついでに xrefs 自体も辿ってみる。
(trace-functions "swank:xrefs")
"swank:xrefs"
"SWANK:XREF"
"SWANK:FROM-STRING"
"SWANK::CALL-WITH-BUFFER-SYNTAX"
"SWANK/BACKEND:CALL-WITH-SYNTAX-HOOKS"
"SB-IMPL::GET3"
"SYMBOL-PLIST"